 當(dāng)前位置:
當(dāng)前位置: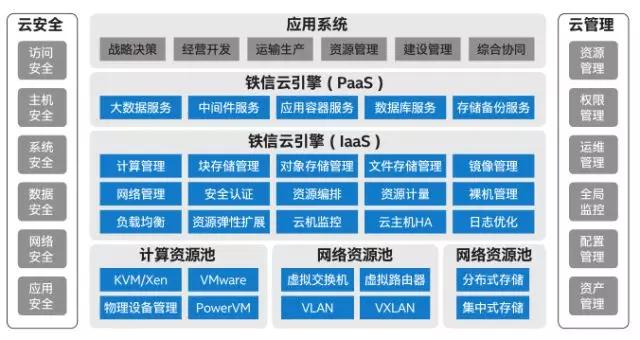
服務(wù)熱線
0755-83647532

發(fā)表日期:2018-01-30 文章編輯:管理員 閱讀次數(shù):
作者:高明星 胡明月 金運(yùn)通
本系列將分三部分,第一部分介紹項(xiàng)目概述和“控制平面性能測試及優(yōu)化
一、項(xiàng)目簡介
鐵路作為一種大眾化的交通工具和非常重要的貨物運(yùn)輸方式,其業(yè)務(wù)規(guī)模龐大、覆蓋全國、服務(wù)全國各族人民。面對時代的變革和向現(xiàn)代物流企業(yè)轉(zhuǎn)型的需要,鐵路IT部門需要建設(shè)更高效靈活、部署簡便、安全可控的IT基礎(chǔ)設(shè)施。為了更好地支持中國鐵路總公司從傳統(tǒng)客貨運(yùn)輸企業(yè)向現(xiàn)代物流企業(yè)轉(zhuǎn)型,中國鐵路信息技術(shù)中心于2014年底決定研發(fā)云計(jì)算解決方案和產(chǎn)品,由此“鐵信云”應(yīng)運(yùn)而生。
為了更好地支持中國鐵路總公司從傳統(tǒng)客貨運(yùn)輸企業(yè)向現(xiàn)代物流企業(yè)轉(zhuǎn)型,中國鐵路信息技術(shù)中心于2014年底決定研發(fā)云計(jì)算解決方案和產(chǎn)品。作為一個大型行業(yè)的OpenStack用戶,中國鐵路總公司希望真正掌握開源技術(shù),安全可控地運(yùn)用在生產(chǎn)中,而不是簡單的產(chǎn)品使用方,同時為了打造用戶與廠商共生互利的OpenStack新商業(yè)生態(tài),“鐵信云”產(chǎn)品采用了業(yè)界創(chuàng)新的聯(lián)合研發(fā)模式,由中國鐵路信息技術(shù)中心牽頭組織,北京中鐵信科技有限公司和北京云途騰科技有限責(zé)任公司一起聯(lián)合研制。
基于鐵路的應(yīng)用及運(yùn)維特點(diǎn),鐵信云要求以“穩(wěn)定性、可靠性、易用性、安全性”為標(biāo)準(zhǔn)對OpenStack進(jìn)行二次開發(fā),解決OpenStack開源架構(gòu)下各種模塊與組件的不足,同時為了滿足鐵路行業(yè)超大規(guī)模行業(yè)云部署實(shí)施,并對業(yè)務(wù)應(yīng)用提供高性能、穩(wěn)定可靠的支撐,Intel聯(lián)合各方一起做了一系列的測試調(diào)優(yōu)和驗(yàn)證工作,主要分為以下3個部分:
控制平面性能測試及優(yōu)化
通過測試來驗(yàn)證鐵信云在單一region下能支撐的最大規(guī)模,尋找在單一region下部署的高效優(yōu)化架構(gòu)設(shè)計(jì)方案,以及在該架構(gòu)下的優(yōu)化參數(shù)配置,以保障其在超大規(guī)模部署和高負(fù)載條件下云服務(wù)能高效、穩(wěn)定、可靠運(yùn)行。
數(shù)據(jù)平面性能測試及優(yōu)化
云平臺承載業(yè)務(wù)的性能及運(yùn)行穩(wěn)定性與云平臺的數(shù)據(jù)平面密切相關(guān),通過對存儲,計(jì)算,網(wǎng)絡(luò)方面的性能測試和優(yōu)化來驗(yàn)證Intel產(chǎn)品及技術(shù)對云平臺數(shù)據(jù)平面的性能支撐,并為生產(chǎn)環(huán)境的部署及配置提供參考和優(yōu)化方法。
關(guān)鍵應(yīng)用負(fù)載Oracle RAC性能測試及優(yōu)化
Oracle RAC數(shù)據(jù)庫作為鐵路信息系統(tǒng)中的關(guān)鍵應(yīng)用,在控制平面及數(shù)據(jù)平面的優(yōu)化驗(yàn)證基礎(chǔ)之上,我們對Oracle RAC在鐵信云環(huán)境中進(jìn)行了部署和驗(yàn)證。
二、鐵信云架構(gòu)介紹
“鐵信云”云平臺目前主要包括基礎(chǔ)設(shè)施服務(wù)層(IaaS)和平臺服務(wù)層(PaaS),整體架構(gòu)如下圖所示:
“鐵信云”的基礎(chǔ)設(shè)施服務(wù)層(IaaS),以O(shè)penStack架構(gòu)為基礎(chǔ),實(shí)現(xiàn)對計(jì)算資源池、存儲資源池和網(wǎng)絡(luò)資源池進(jìn)行統(tǒng)一管理和調(diào)度,為信息系統(tǒng)應(yīng)用部署提供基礎(chǔ)資源服務(wù)。計(jì)算資源池支持對KVM、VMware、X86裸機(jī)、Power設(shè)備等多種資源的統(tǒng)一管理;存儲資源池支持對基于X86服務(wù)器的分布式存儲和基于傳統(tǒng)商用存儲等多種資源的統(tǒng)一管理;網(wǎng)絡(luò)資源池支持對VLAN、VxLAN等多種模式下的物理和虛擬網(wǎng)絡(luò)資源的統(tǒng)一管理。
“鐵信云”的平臺服務(wù)層(PaaS),為應(yīng)用運(yùn)行提供數(shù)據(jù)庫、中間件、大數(shù)據(jù)、數(shù)據(jù)備份等平臺軟件的統(tǒng)一部署服務(wù);提供數(shù)據(jù)抽取、分析、存儲及展示等服務(wù),同時基于容器技術(shù)提供應(yīng)用快速部署及遷移服務(wù)。
“鐵信云”還根據(jù)大規(guī)模部署等需求,不斷改進(jìn)完善云平臺功能。例如改進(jìn)了云主機(jī)監(jiān)控方式,舍棄了Ceilometer的監(jiān)控功能,集成了Open-Falcon;增加了日志審計(jì)模塊,便于管理員和租戶查閱操作日志;實(shí)現(xiàn)了云主機(jī)HA,支持物理主機(jī)故障時云主機(jī)自動遷移,等等。
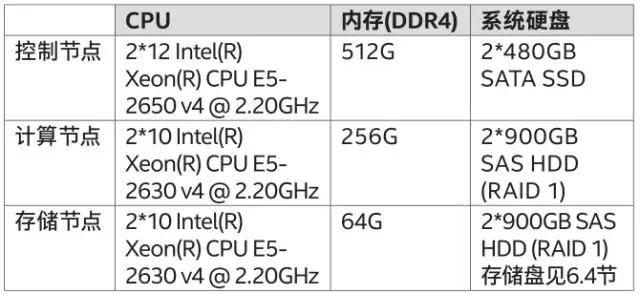
“鐵信云”一期項(xiàng)目大規(guī)模部署環(huán)境中包括一個由780個物理節(jié)點(diǎn)構(gòu)成的云系統(tǒng),其中有3個控制節(jié)點(diǎn)、600個主機(jī)作為計(jì)算節(jié)點(diǎn),網(wǎng)絡(luò)節(jié)點(diǎn)在計(jì)算節(jié)點(diǎn)上、117個存儲節(jié)點(diǎn)等。
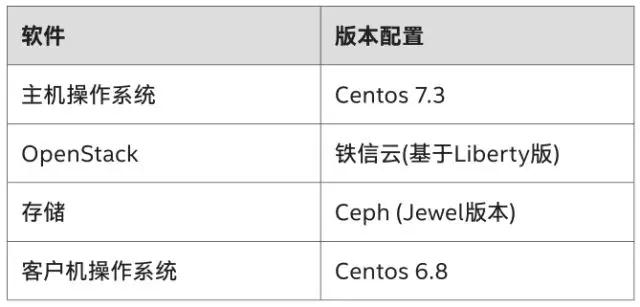
本次大規(guī)模優(yōu)化驗(yàn)證基于以上鐵信云780個節(jié)點(diǎn)的系統(tǒng),主要軟硬件設(shè)備及基本配置如下表所示:
三、控制平面性能測試及優(yōu)化
控制平面是指在云環(huán)境下為實(shí)現(xiàn)IT資源的統(tǒng)一管理和調(diào)度而設(shè)備互聯(lián)形成的網(wǎng)絡(luò),設(shè)備包括控制節(jié)點(diǎn)和被管控的計(jì)算、存儲、網(wǎng)絡(luò)等資源節(jié)點(diǎn);建立控制平面的目的是通過充分利用IT資源以更好地滿足業(yè)務(wù)應(yīng)用運(yùn)行需求。
控制平面的性能是云平臺大規(guī)模部署的基礎(chǔ)和關(guān)鍵,大規(guī)模行業(yè)云的控制平面部署設(shè)計(jì)有多種方案,如單一region規(guī)模化部署、多region部署、多cell等模式,無論哪種模式,單一region下的規(guī)模部署是基礎(chǔ)。通過測試來驗(yàn)證鐵信云在單一region下能支撐的最大規(guī)模,試圖尋找在單一region下部署的高效優(yōu)化架構(gòu)設(shè)計(jì)方案,以及在該架構(gòu)下的優(yōu)化參數(shù)配置,以保障其在超大規(guī)模部署和高負(fù)載條件下云服務(wù)能高效、穩(wěn)定、可靠運(yùn)行。
3.1 控制平面測試介紹
3.1.1 測試目的及方法
此次案例以探索單region的規(guī)模和性能邊界為目標(biāo)做了測試和優(yōu)化,最終希望利用現(xiàn)有經(jīng)驗(yàn)探索大規(guī)模數(shù)據(jù)中心的云平臺部署最佳實(shí)踐:
• 觀察一定規(guī)模計(jì)算節(jié)點(diǎn)下創(chuàng)建云主機(jī)壓力對控制節(jié)點(diǎn)集群的影響,例如CPU、內(nèi)存、網(wǎng)絡(luò)IO、磁盤IO等,為今后大規(guī)模云數(shù)據(jù)中心的云平臺設(shè)計(jì)、擴(kuò)容提供數(shù)據(jù)基礎(chǔ)。
• 并發(fā)及資源利用率考量。來自用戶的并發(fā)請求對整體系統(tǒng)穩(wěn)定性的考量,即尋找數(shù)據(jù)庫、RabbitMQ集群和OpenStack組件瓶頸,期望通過改良系統(tǒng)參數(shù)、服務(wù)配置、代碼邏輯,在服務(wù)穩(wěn)定的前提下最大化提高物理資源的使用效率。
我們依次對100、200、300、400、500、600物理計(jì)算節(jié)點(diǎn)做了多輪測試及優(yōu)化:
• 通過固定計(jì)算節(jié)點(diǎn)數(shù),以1:20的比例(1臺計(jì)算節(jié)點(diǎn)創(chuàng)建20臺云主機(jī))分批次創(chuàng)建相應(yīng)數(shù)量的云主機(jī),通過查詢數(shù)據(jù)庫和日志信息可以計(jì)算獲得其創(chuàng)建成功率,通過分析日志,對每臺創(chuàng)建成功的云主機(jī),都可以計(jì)算得到它在創(chuàng)建過程中各模塊的時間消耗,并以此衡量創(chuàng)建云主機(jī)的性能。
• 針對RabbitMQ的分析,基于一組以1:2的比例(1臺計(jì)算節(jié)點(diǎn)創(chuàng)建2臺云主機(jī))分批次創(chuàng)建云主機(jī)的場景,用以獲取準(zhǔn)確的實(shí)際消息數(shù)目,建立基準(zhǔn)模型供后續(xù)分析參考驗(yàn)證。基于此,利用監(jiān)控?cái)?shù)據(jù)定性分析在1:20比例下的優(yōu)化效果。
• 模擬多API同時觸發(fā),針對失敗的請求,結(jié)合系統(tǒng)返回的信息和日志觀察,分析錯誤原因。
• 通過用一些性能監(jiān)測工具對創(chuàng)建云主機(jī)過程進(jìn)行性能評測。
3.2 控制平面性能測試分析及優(yōu)化
先對社區(qū)默認(rèn)的參數(shù)配置進(jìn)行測試,通過對日志數(shù)據(jù)的收集和分析發(fā)現(xiàn)大規(guī)模部署中的瓶頸所在,并逐步加以優(yōu)化和驗(yàn)證,最終得出大規(guī)模部署下最佳配置和部署實(shí)踐。
3.2.1 第一輪參數(shù)優(yōu)化調(diào)
社區(qū)默認(rèn)配置無法直接承載600+計(jì)算節(jié)點(diǎn)規(guī)模,表征如下:
• RabbitMQ連接超時,如圖4-1和4-2所示
• 無法執(zhí)行創(chuàng)建、獲取資源等任務(wù)
• Keystone無法響應(yīng)等
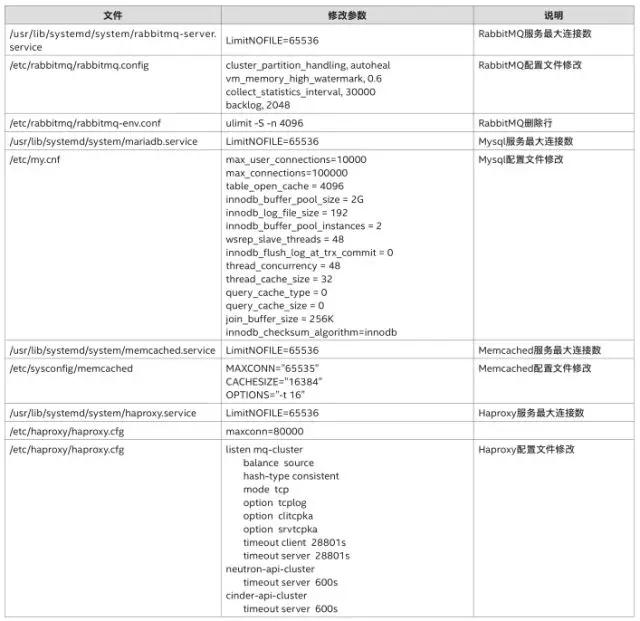
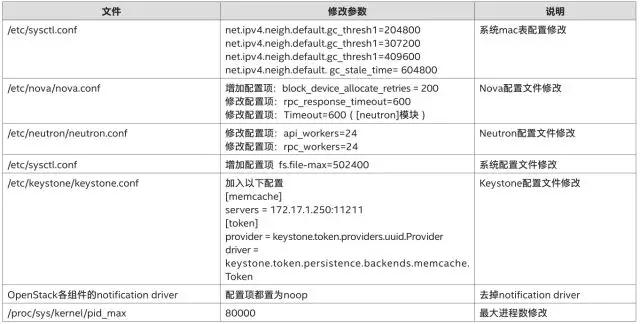
第一輪參數(shù)優(yōu)化調(diào)整的目標(biāo)是為了滿足大規(guī)模節(jié)點(diǎn)部署的應(yīng)用場景,使云管理平臺能夠基本正常運(yùn)行。如下表所示,我們對系統(tǒng)參數(shù)、數(shù)據(jù)庫配置、OpenStack組件分別根據(jù)需求做了調(diào)整。
例如,操作系統(tǒng)方面,我們調(diào)整了最大文件描述符、最大線程數(shù),以提高單個系統(tǒng)吞吐能力;數(shù)據(jù)庫方面,我們調(diào)整了openfile限制,調(diào)大了查詢緩存,以提高數(shù)據(jù)庫節(jié)點(diǎn)的整體性能;OpenStack方面,我們根據(jù)自身環(huán)境情況做了RPC相關(guān)的服務(wù)配置,以緩解服務(wù)端壓力。
經(jīng)過上述第一輪參數(shù)配置修改后,600+節(jié)點(diǎn)構(gòu)成的云平臺工作正常,并能正常對外提供服務(wù)。
3.2.2 第二輪參數(shù)優(yōu)化調(diào)整
第二輪參數(shù)優(yōu)化調(diào)整的目標(biāo)是為了進(jìn)一步提高云平臺運(yùn)行的穩(wěn)定性和可靠性。經(jīng)過上述第一輪參數(shù)調(diào)整,在高并發(fā)和高負(fù)載條件下創(chuàng)建云主機(jī),仍然還存在較高的失敗率。為更好地了解創(chuàng)建云主機(jī)流程和錯誤性質(zhì),我們分析了3組場景(200、400、600計(jì)算節(jié)點(diǎn),以1:20比例創(chuàng)建云主機(jī))的詳細(xì)日志以及數(shù)據(jù)庫中的所有相關(guān)信息。在全部24000個請求中,我們成功追蹤到所有請求,其中17703個請求成功完成,成功率僅為73.76%。
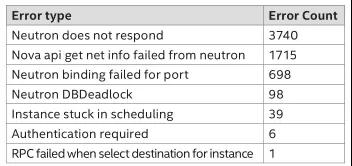
我們對創(chuàng)建過程中的錯誤進(jìn)行了分類,下表展示了錯誤分布情況。基于分詞、特征提取以及聚類建模分析,我們得到關(guān)鍵錯誤信息,消除了重復(fù)和不相關(guān)的信息.
3.2.2.1兩大錯誤問題分析
列出了的幾種錯誤表現(xiàn)形式,可以主要?dú)w納為以下兩大錯誤類型:
• 消息隊(duì)列相關(guān)問題:在壓力太大的情況下,RabbitMQ集群不穩(wěn)定因素會導(dǎo)致隊(duì)列同步失敗,最終消息丟失, 或者直接導(dǎo)致隊(duì)列消失,消費(fèi)者無法拿到消息等。因此出現(xiàn),Neutron linuxbridge agent上報狀態(tài)失敗,neutron-server誤認(rèn)為與port綁定的linuxbridge agent處于dead狀態(tài),導(dǎo)致port綁定失敗;Nova通過RPC與nova-scheduler交互選擇host主機(jī)失敗導(dǎo)致選擇主機(jī)失敗、與nova-compute交互執(zhí)行創(chuàng)建云主機(jī)操作失敗導(dǎo)致云主機(jī)一直處于scheduling狀態(tài)等情況。
• 數(shù)據(jù)庫問題:一方面,數(shù)據(jù)庫表死鎖,主要集中在Neutron創(chuàng)建port分配IP的過程中,并發(fā)分配網(wǎng)絡(luò)IP時會導(dǎo)致資源爭搶;另一方面,在nova-compute準(zhǔn)備網(wǎng)絡(luò)資源、及nova-api檢驗(yàn)請求網(wǎng)絡(luò)信息時與Neutron交互的過程中,由于數(shù)據(jù)庫讀寫較慢導(dǎo)致Neutron處理請求過慢,無法響應(yīng)Nova的請求。
3.2.2.2參數(shù)再次優(yōu)化調(diào)整
經(jīng)進(jìn)一步調(diào)查研究發(fā)現(xiàn),表4-2列出的異常及錯誤問題,可采用如下方法規(guī)避并進(jìn)一步調(diào)優(yōu)。
• 適 當(dāng)增 加 N e u t r o n 配 置中的 a ge nt _ d ow n _ t i m e,避 免linuxbridge agent出現(xiàn)僵死的現(xiàn)象。適當(dāng)增加Nova配置文件的the service_down_time,避免novascheduler調(diào)度過程中出現(xiàn)nova-compute僵死的現(xiàn)象。
• 將Nova配置文件中的the rpc_response_timeout設(shè)置為更長的時間,允許更長的時間等待nova-scheduler調(diào)度。
經(jīng)過上述參數(shù)優(yōu)化調(diào)整后,可以在一定程度上緩解創(chuàng)建云主機(jī)的失敗率。完成第二輪參數(shù)優(yōu)化調(diào)整后,我們再次在相同的3個場景下,共創(chuàng)建24000臺云主機(jī),成功率由73.76%上升至84.50%。但是仍然有一部分錯誤需要解決,接下來我們對2大錯誤問題根源入手進(jìn)行更深層次的分析優(yōu)化。
3.2.3消息統(tǒng)計(jì)模型及消息通信架構(gòu)調(diào)整
測試過程中,伴隨集群規(guī)模擴(kuò)大(主要是計(jì)算節(jié)點(diǎn)增加),服務(wù)端對成功響應(yīng)創(chuàng)建請求的占比有所下降。通過進(jìn)一步對錯誤日志分析,在創(chuàng)建過程中,通常會出現(xiàn)以下幾類異常:
• 消息隊(duì)列丟失導(dǎo)致云主機(jī)一直處于調(diào)度狀態(tài)(已經(jīng)選出主機(jī),但是計(jì)算節(jié)點(diǎn)沒有處理相關(guān)任務(wù),云主機(jī)狀態(tài)也不會變成error)
• 各服務(wù)連接RabbitMQ失敗并不斷重連
• 處理創(chuàng)建請求的過程中RabbitMQ崩潰針對消息隊(duì)列壓力過大的問題,我們對比配置了nova-conductor的兩種API模式,由rpc改為local模式;另一方面,notification driver配置為noop。
這些措施一定程度上減少了消息隊(duì)列的負(fù)荷。同時,我們結(jié)合源碼對測試數(shù)據(jù)進(jìn)行分析,先從源碼中匯總創(chuàng)建過程中出現(xiàn)的rpc方法,再根據(jù)涉及的rpc類型估計(jì)相應(yīng)的消息數(shù)目,最后得到關(guān)于創(chuàng)建請求產(chǎn)生的消息總數(shù)的計(jì)算模型,通過分析測試過程中RabbitMQ產(chǎn)生的的trace日志,可以獲取實(shí)際消息數(shù)目。但考慮到大規(guī)模創(chuàng)建對RabbitMQ的壓力,我們采取的是小規(guī)模(按照1:2的比例為每個計(jì)算節(jié)點(diǎn)創(chuàng)建云主機(jī))定量驗(yàn)證模型,大規(guī)模定性分析優(yōu)化結(jié)果的方法。在小規(guī)模環(huán)境下,經(jīng)過對比,實(shí)際消息數(shù)與我們的模型分析結(jié)果一致。
結(jié)果表明,消息總數(shù)和計(jì)算節(jié)點(diǎn)數(shù)緊密相關(guān),會隨著計(jì)算節(jié)點(diǎn)規(guī)模的增加而迅速增加,分析發(fā)現(xiàn)主要消息來源是neutron-server向linuxbridge agent發(fā)送l2 population和安全組信息的廣播涉及的兩個方法:securitygroups_member_updated和add_fdb_entries。例如600個節(jié)點(diǎn)會產(chǎn)生千萬級別 [注1] 的消息經(jīng)由消息隊(duì)列處理, 而l2 population和安全組的消息占這個消息總數(shù)的90%以上。因此我們將這兩類消息進(jìn)行了剝離,以減輕RabbitMQ的負(fù)擔(dān).
通過分析OpenStack服務(wù)的行為,我們可以成功評估所需消息隊(duì)列節(jié)點(diǎn)的規(guī)模,并對未來集群規(guī)模做科學(xué)的制定和規(guī)劃。
3.2.4 OpenStack組件數(shù)據(jù)庫負(fù)載分析及優(yōu)化
前文描述過,在并發(fā)創(chuàng)建的時候,由于neutron在分配IP地址時,會發(fā)生嚴(yán)重的資源爭搶,這在高并發(fā)下會導(dǎo)致請求緩慢,甚至請求超時的錯誤發(fā)生。通過仔細(xì)分析,這是由于在liberty版本中,IP地址的分配是通過select…for update語句觸發(fā),該類語句會在數(shù)據(jù)庫層獲取相關(guān)行的intend lock,高并發(fā)情況下,同一子網(wǎng)內(nèi)的IP分配請求都會對該子網(wǎng)所對應(yīng)的數(shù)據(jù)庫表的intend lock進(jìn)行爭搶。
從而導(dǎo)致資源忙等待超時,在業(yè)務(wù)層面就會表現(xiàn)出數(shù)據(jù)庫 deadlock。雖然在業(yè)務(wù)層面對該類異常進(jìn)行了重試,但在實(shí)際的測試中發(fā)現(xiàn)分配成功率并沒有得到太大的改善。
而在mitaka版本之后, IP分配方式得以改進(jìn)。更改后的邏輯不再使用select…for update的方式獲得結(jié)果,而是組合了select語句配合一個窗口值隨機(jī)分配IP地址。因?yàn)橄嚓P(guān)的IP分配流程都在內(nèi)存中進(jìn)行,這就避免了IPAvailabilityRanges表加鎖,我們更新(backport)了相關(guān)patch,圖4-6中對比了修改IP分配邏輯前后的rally測試結(jié)果。兩張結(jié)果對比了更新patch前后并發(fā)創(chuàng)建port時的成功率及耗時。可以看到社區(qū)的patch修復(fù)效果較為明顯,并發(fā)創(chuàng)建240個port成功率和耗時上都較修復(fù)前有了較大的改進(jìn)。
在測試過程中,我們也嘗試通過其他的架構(gòu)來提高數(shù)據(jù)庫的并發(fā)事務(wù)能力,我們通過在數(shù)據(jù)庫系統(tǒng)中開啟dtrace探針來分析云主機(jī)生成期間數(shù)據(jù)庫的訪問行為,例如分析OpenStack不同項(xiàng)目數(shù)據(jù)庫的訪問熱度、CUID(create,update,insert,delete)執(zhí)行比例及耗時等。
發(fā)現(xiàn)在云主機(jī)并發(fā)創(chuàng)建期間,OpenStack不同項(xiàng)目的CUID占比。我們可以看到neutron, nova SELECT讀的占比分別達(dá)到82.1%(1972/2400)和62.1%(2356/3790)
因此,當(dāng)數(shù)據(jù)庫集群主節(jié)點(diǎn)負(fù)荷較高時,我們可以通過在數(shù)據(jù)庫集群和sqlachemy之間增加數(shù)據(jù)庫代理來分發(fā)讀寫請求。當(dāng)然,這首先需要在業(yè)務(wù)層增加額外的代碼來幫助數(shù)據(jù)庫代理層識別讀事務(wù)與寫事務(wù)請求,數(shù)據(jù)庫代理會透明的將讀事務(wù)和寫事務(wù)分發(fā)到不同的數(shù)據(jù)庫實(shí)例上,這可以有效的提高數(shù)據(jù)庫的并發(fā)事務(wù)能力。
3.2.5綜合優(yōu)化前后云主機(jī)創(chuàng)建請求成功率及耗時分析
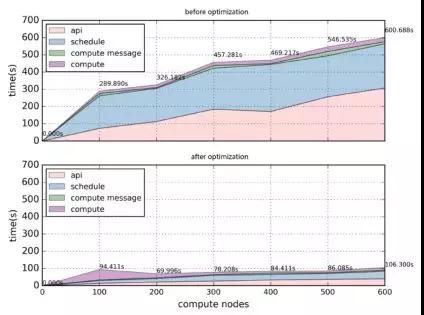
經(jīng)過部分參數(shù)調(diào)優(yōu)后,集群規(guī)模從100依次增長到600個節(jié)點(diǎn)時,由于數(shù)據(jù)庫、RabbitMQ、OpenStack組件服務(wù)的原因創(chuàng)建云主機(jī)的成功率從100%逐漸衰減到80%。描述nova-api、nova-scheduler、控制節(jié)點(diǎn)nova服務(wù)向計(jì)算節(jié)點(diǎn)發(fā)送RPC消息、nova-compute這四部分組件級別耗時)對比了相同規(guī)模相同壓力下,RabbitMQ和數(shù)據(jù)庫進(jìn)一步調(diào)優(yōu)前后,按照每個計(jì)算點(diǎn)20臺云主機(jī)的比例創(chuàng)建云主機(jī)過程的平均耗時。可以看到,隨著集群規(guī)模增加,創(chuàng)建耗時逐漸增長,當(dāng)集群規(guī)模增長到600個節(jié)點(diǎn)時,單臺云主機(jī)創(chuàng)建平均耗時可達(dá)到600s左右。在前面的基礎(chǔ)上,通過對大量日志及相關(guān)監(jiān)控?cái)?shù)據(jù)的進(jìn)一步分析,我們發(fā)現(xiàn)nova-api等待neutron-server返回網(wǎng)絡(luò)信息時間較長,導(dǎo)致novaapi耗時較長,同時,nova-scheduler處理時間也較長,根源還是在于數(shù)據(jù)庫和RabbitMQ的性能限制了云平臺處理請求的能力。
經(jīng)過RabbitMQ和數(shù)據(jù)庫進(jìn)行進(jìn)一步調(diào)整優(yōu)化后,nova-scheduler調(diào)度效率提高了20倍, neutron-server的吞吐提高了90%。優(yōu)化后,并發(fā)創(chuàng)建云主機(jī)的成功率幾乎不受集群規(guī)模的影響,沒有明顯波動,穩(wěn)定在100%附近;平均創(chuàng)建時間也比優(yōu)化前也有明顯縮短。
文章摘自英特爾精英匯
寶通集團(tuán)聯(lián)系方式
咨詢熱線:0755-88603572
寶通官網(wǎng):www.bjrongxin.com
客戶垂詢郵箱:cuifang.mo@ex-channel.com
客戶垂詢QQ:1627678462
地址:深圳市福田區(qū)深南大道1006號國際創(chuàng)新中心C座11樓
郵編:51802


 粵公網(wǎng)安備 44030402001885號
友情鏈接: 金沙古酒 | 中青寶 | 寶德控股 | 寶德計(jì)算 |
粵公網(wǎng)安備 44030402001885號
友情鏈接: 金沙古酒 | 中青寶 | 寶德控股 | 寶德計(jì)算 |