英特爾® 傲騰™ 固態盤 DC P4800X 和英特爾® IMDT 將 Apache Spark* 的吞吐量增加一倍,同時將運行時間縮短 40%。

要點綜述
Apache Spark* 是一種常見的數據處理引擎,用于對超大數據集進行高級分析。在當今涉及基于云的服務、物聯網和機器學習的企業用例中,這類數據已經司空見慣。Spark 采用了一個通用的集群計算框架,能夠獲取和處理實時的超大數據流,即時處理和分析事件和異常情況,從而支持企業快速制定決策,更好地響應用戶需求。
為了使 Spark 能夠在運行不同工作負載(例如機器學習應用)時實現卓越性能,Spark 內置了內存數據存儲功能。因此,Spark 的性能要明顯優于其他大數據處理技術。但是,Spark 內存功能受到服務器中可用內存的限制;受此影響,我們在執行 Spark 作業期間經常可以看到的一種情況是,系統內存已經飽和,但計算資源卻處于閑置狀態。要消除這種限制,一種辦法為在節點集群上運行 Spark 的分布式架構,以充分利用所有節點中的可用內存。雖然采用更多節點可以解決服務器 DRAM 容量問題,但會增加成本。DRAM 不僅成本高昂,而且還要求運營商配置額外的服務器以獲得更多內存。
英特爾® IMDT(Intel Memory Drive Technology)是一種軟件定義內存(SDM)技術,與英特爾® 傲騰™ 固態盤相結合使用時,可有效擴展系統內存。這種英特爾® 傲騰™ 固態盤與英特爾® IMDT 的結合,可以透明地為操作系統和 Spark 作業提供更多內存,消除 Spark 應用所固有的內存限制。為了演示此功能,英特爾使用了一種當前名為 TeraSort 的 Spark 性能指標評測程序。1 該程序測試得出的初始數值顯示,英特爾® IMDT 能夠有效提升資源利用率,改進系統性能。
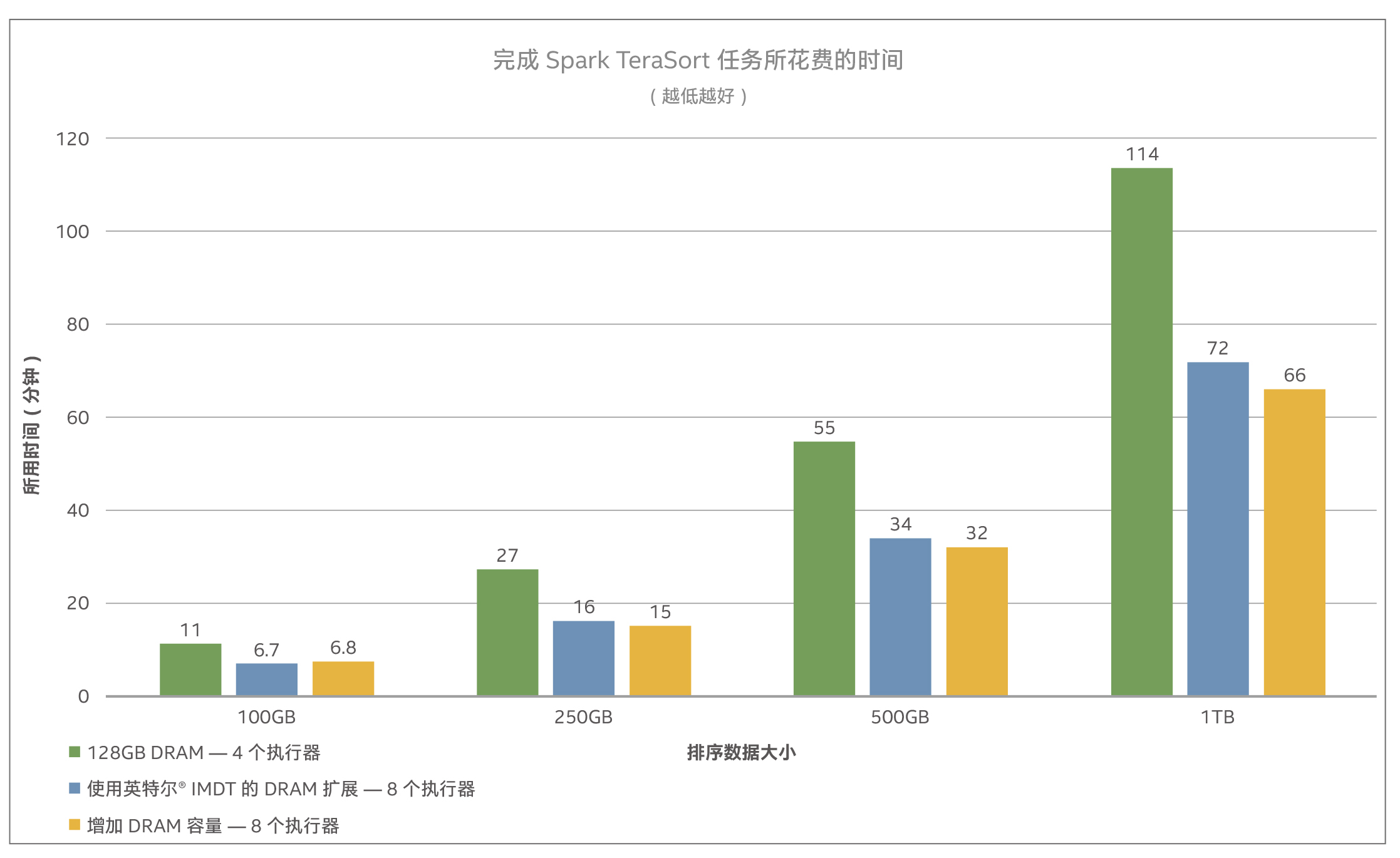
這一內存擴展方法可通過使用英特爾® IMDT 顯著加大系統內存,同時通過運行更多的 Spark 執行器,充分利用系統計算容量。該性能指標評測程序表明,在具有相同內存和計算能力的系統上,通過添加英特爾® IMDT 軟件,可以將 Spark 作業吞吐量提高一倍。相對于使用用英特爾® IMDT,另一種方法是為系統添加更多 DRAM。如圖 3 的性能指標評測結果所示,添加更多 DRAM 只能略微提高性能,但成本卻要顯著高于英特爾® IMDT。
本技術簡介比較了這兩種備選方案,確定了各自的性能增益,然后將性能增益與總體擁有成本(TCO)增益進行了對比。
性能指標評測方法
TeraSort* 是一種常見的性能指標評測程序,用于測量在特定計算機系統上對 1 TB 隨機分布數據進行排序所需的時間。它最初是一種用于測量 Apache Hadoop* 集群的 MapReduce* 性能的常用方法,并且有一些用于 Spark 的變體。在數據處理中,傳入的數據必須先排序才能進行分析或處理,因此排序性能至關重要。而這也說明了該性能指標評測套件如此流行的原因所在。
系統配置
表 1 列出了測試的三個不同場景的系統配置。這三種配置包括:基準 DRAM 配置;基準配置加英特爾® IMDT,以增加內存容量;以及與僅增加 DRAM 的比較。
表 1:比較配置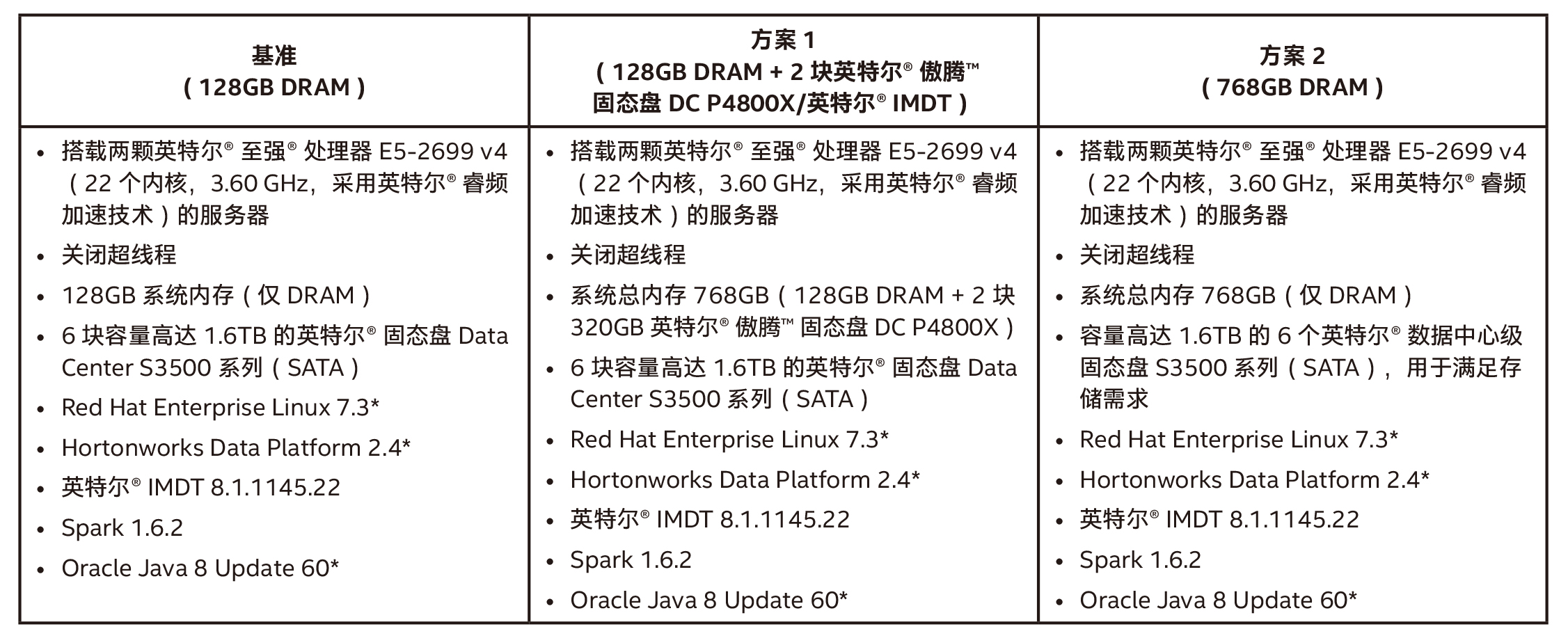
測試方法
數據有4種大小:100GB、250GB、500GB 和 1Tb,使用 3 種不同的執行器數量。
圖 1:軟件堆棧 圖 2:Spark 執行器進程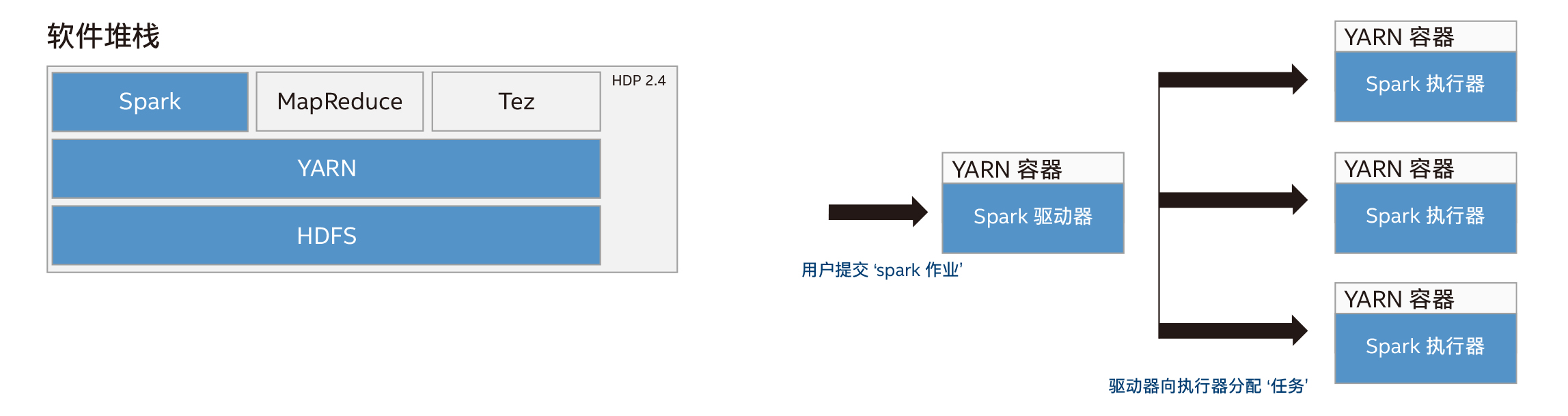
Spark 驅動器和執行器是 JVM(Java 虛擬機)進程。Spark 執行器使用的內核和內存均可配置;在這些測試中,Spark 驅動器的內存為 7.5GB,Spark 執行器的內存為 21GB。
圖 3:性能指標評測結果
結論
測試表明,通過在運行基于 Spark 的 TeraSort 工作負載的單個服務器節點上,使用英特爾® IMDT 添加兩塊用英特爾
® 傲騰™ 固態盤 DCP4800X,吞吐量提高了一倍,同時運行時間縮短了多達 40%。而在向系統添加更多 DRAM 的方案中,性能相比于 IMDT 的方案略有提高。然而,要實現這一不到 6% 的性能提升,成本需要增加大約 50%。相比之下,英特爾® IMDT 軟件憑借更低的成本(在本文的比較中,成本大約是 DRAM 成本的一半3),以及所能實現的更高容量(英特爾® IMDT 可在雙路節點中添加 1280-3200 GB 的系統內存4),在總體擁有成本方面明顯具有更高的優勢。
想購買及了解更多英特爾® 傲騰™ 固態盤DC P4800X系列產品詳情,歡迎咨詢以下聯系方式!
寶通集團聯系方式
咨詢熱線:0755-88603572
寶通官網:www.bjrongxin.com
客戶垂詢郵箱:cuifang.mo@ex-channel.com
客戶垂詢QQ:1627678462
地址:深圳市福田區深南大道1006號國際創新中心C座11樓
郵編:518026
 當前位置:
當前位置:


 粵公網安備 44030402001885號
友情鏈接: 金沙古酒 | 中青寶 | 寶德控股 | 寶德計算 |
粵公網安備 44030402001885號
友情鏈接: 金沙古酒 | 中青寶 | 寶德控股 | 寶德計算 |