大數(shù)據(jù)時代,數(shù)據(jù)量呈幾何增長,為避免被時代潮流“拍在沙灘上”,就必須了解大數(shù)據(jù)的核心組成要素。其中,海量日志尤為重要,不管是IT達(dá)人還是企業(yè)本身,掌握海量日志的分析技術(shù)都必不可少。今天,就讓小編帶你探秘海量日志分析技術(shù),一起來看吧。
為什么海量日志很重要?
在討論海量日志分析技術(shù)之前,我們先來討論一下什么是海量日志。海量日志是大數(shù)據(jù)的重要組成部分。數(shù)據(jù)倉庫之父比爾.恩門(Bill Inmon) 在他的2016年的新書《數(shù)據(jù)架構(gòu)》中提到,企業(yè)中數(shù)據(jù)的組成部分中,非結(jié)構(gòu)化的數(shù)據(jù)占比已經(jīng)達(dá)到了 70% 以上。而這些非結(jié)構(gòu)化數(shù)據(jù)中,占據(jù)主導(dǎo)位置的是日志數(shù)據(jù),可以說日志數(shù)據(jù)是“大數(shù)據(jù)”分析的核心。這些數(shù)據(jù)貫穿所有的企業(yè)經(jīng)營活動,用戶的操作行為、服務(wù)器的系統(tǒng)日志、網(wǎng)絡(luò)設(shè)備的日志記錄、應(yīng)用程序的調(diào)試日志等等,會直接影響企業(yè)的日常運(yùn)行,與IT運(yùn)維人員也是息息相關(guān)。
海量日志數(shù)據(jù)有什么特征?
海量的日志數(shù)據(jù)十分滿足大數(shù)據(jù)的4V特征:產(chǎn)生速度快,每秒超過數(shù)萬、數(shù)十萬的情況已經(jīng)比比皆是;數(shù)據(jù)量巨大,速度一快,如果想要分析這數(shù)據(jù),勢必會帶來巨大的數(shù)據(jù)量;數(shù)據(jù)種類多,日志數(shù)據(jù)涵蓋IT系統(tǒng)的方方面面;價值密度低,雖然日志數(shù)據(jù)中能夠分析出大量有價值的信息,往往一條分析結(jié)果需要數(shù)百萬甚至上億條的數(shù)據(jù)支撐,而且單條日志的信息量有限。
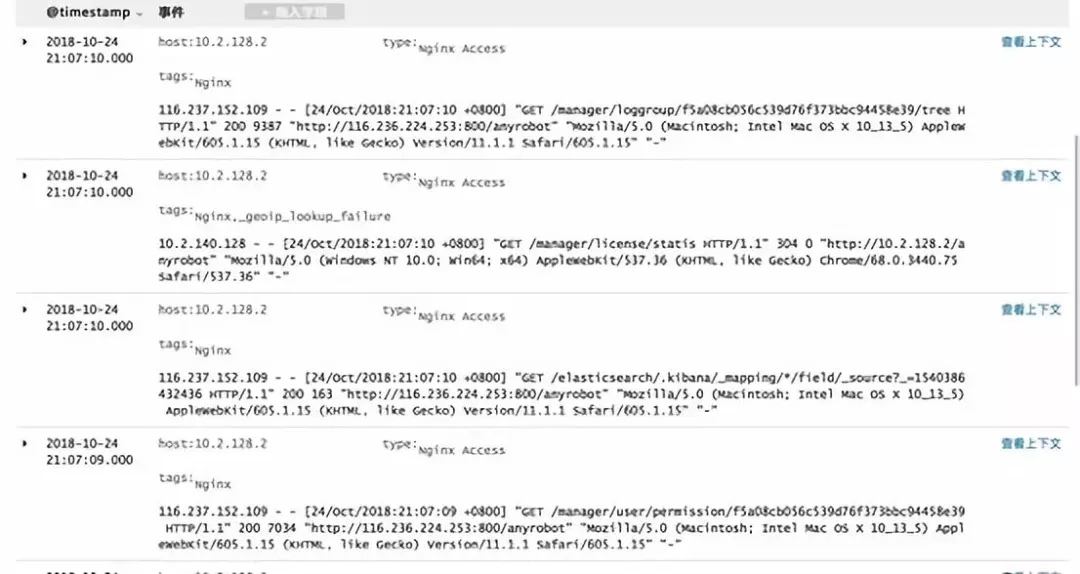 日志樣例
日志樣例 大數(shù)據(jù)時代計算方式的變革從行式存儲到列式存儲,再到流式計算
大數(shù)據(jù)時代計算方式的變革從行式存儲到列式存儲,再到流式計算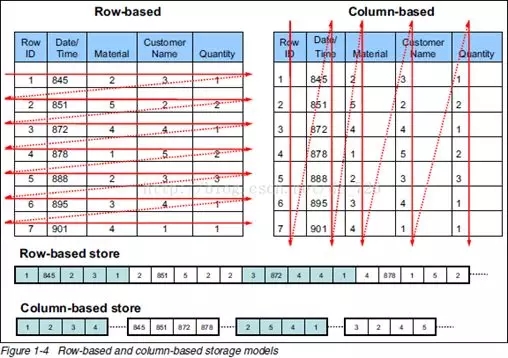 行式數(shù)據(jù)庫vs列式數(shù)據(jù)庫
行式數(shù)據(jù)庫vs列式數(shù)據(jù)庫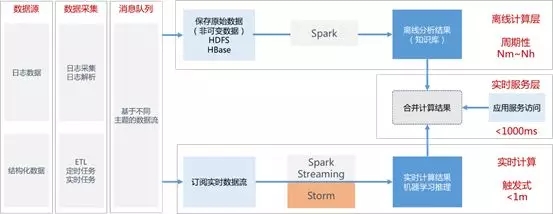 海量日志分析技術(shù)數(shù)據(jù)流程圖海量日志技術(shù)有哪些要點(diǎn)?
海量日志分析技術(shù)數(shù)據(jù)流程圖海量日志技術(shù)有哪些要點(diǎn)?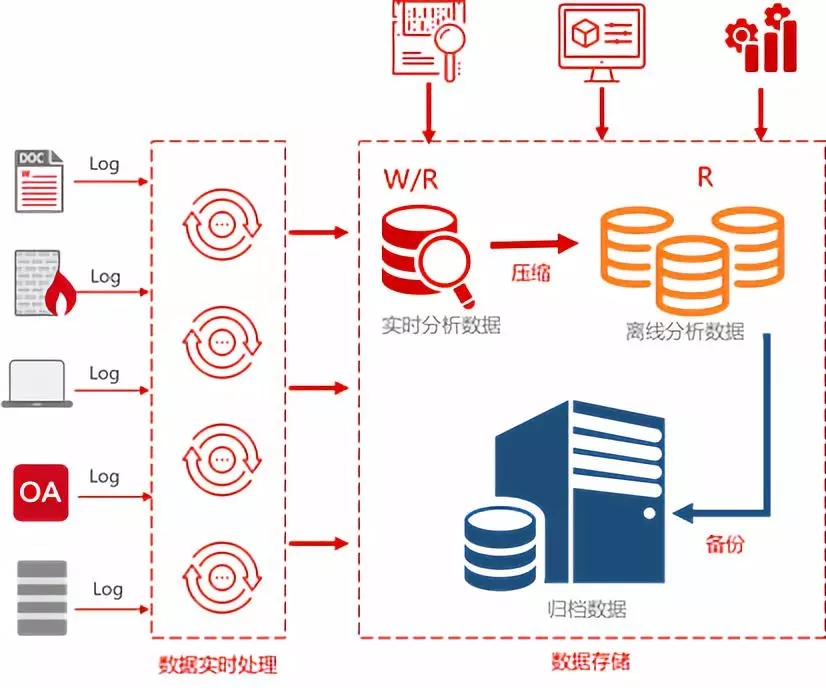 數(shù)據(jù)分層存儲
數(shù)據(jù)分層存儲結(jié)語
日志是大數(shù)據(jù)的重要組成,為了滿足海量日志分析的需要,我們需要從海量日志處理、存儲和分析三個方面來設(shè)計我們的日志分析系統(tǒng)。愛數(shù) AnyRobot Family 3.0 通過加入消息隊(duì)列、流式處理、存儲分層、離線分析、機(jī)器學(xué)習(xí)等特性,是的海量日志分析的的效率和用戶體驗(yàn)都得到了大幅的提升。
文章摘自愛數(shù)
歡迎聯(lián)系寶通集團(tuán)咨詢愛數(shù)產(chǎn)品信息
寶通集團(tuán)聯(lián)系方式
咨詢熱線:0755-88603572
寶通官網(wǎng):www.bjrongxin.com
客戶垂詢郵箱:cuifang.mo@ex-channel.com
客戶垂詢QQ:1627678462
地址:深圳市福田區(qū)深南大道1006號國際創(chuàng)新中心C座11樓
郵編:518026
 當(dāng)前位置:
當(dāng)前位置:


 粵公網(wǎng)安備 44030402001885號
友情鏈接: 金沙古酒 | 中青寶 | 寶德控股 | 寶德計算 |
粵公網(wǎng)安備 44030402001885號
友情鏈接: 金沙古酒 | 中青寶 | 寶德控股 | 寶德計算 |